Introduction
If you are near or at your quota for file storage on your home directory or project space (see this tutorial on the myquota command), it's time to clean up. But how do you do this efficiently? This tutorial will help you to quickly find the largest (sub)directories in your homedir in terms of file size, or file counts, so that you can clean up your home directory or project space efficiently.
The NCDU program
NCDU (or NCurses Disk Usage) is a small program designed to analyse disk usage, with a simple but effective textual interface. It is available from the module environment, e.g.
$ module av ncdu ---------------- /sw/arch/Centos8/EB_production/2021/modulefiles/tools ---------------- ncdu/1.16-GCC-10.3.0
First, we load the module. Then, we execute the 'ncdu' command. Below, you see an example of me having executed the 'ncdu' command in my home directory
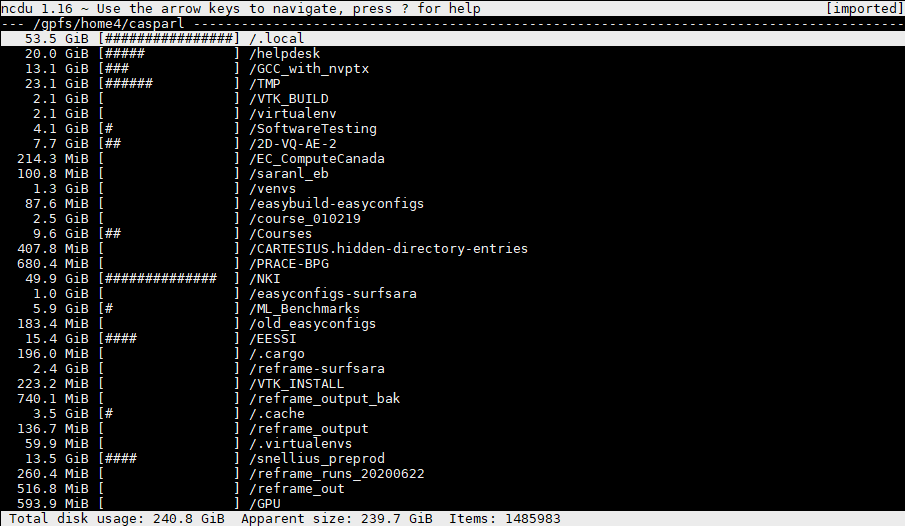
The ncdu interface allows us to browse our directory tree: simply navigate with the arrows, and press 'enter' to enter a directory. Note that ncdu by default will analyse anything inside the current directory. Thus, by executing ncdu in the root of your home directory, you get a full overview of your home directory.
Storing the results of NCDU in a file
Having NCDU perform an analysis on your entire home directory may take quite a long time. If you want to come back to your results later, you can have ncdu store the results in a file by executing
ncdu -o disk_usage.txt
You can then later view this analysis using
ncdu -f disk_usage.txt
Using NCDU to free up space
As an example, let's inspect my '.local' directory, which is clearly consuming the most storage:

As you can see, there is one directory that is responsible for nearly the entire size of my '.local' folder, and that's the 'easybuild' folder. This contains software installations that I have performed locally, and since we test quite a lot of software installations before deploying these in the module environment, it has become quite big. Let's go a few levels deeper:

We see that my CUDA installations take up quite a bit of space. Let's look inside the CUDA folder

I actually don't need these CUDA installations any more, so this gives me an easy opportunity to free up 15 GB of storage.
Of course, software is just an example of the things that can take up space in your homedir. For you, it might be something entirely different, e.g. you might have datasets, or outputs of simulations that take up the most space. Whatever it is, ncdu is a convenient tool to help you identify what takes up the most space, and have you consider if you still really need that. Removing this data entirely is of course not the only option: if it's simulation output, you may want to move this to local storage so that you can free up space in your homedir on Snellius.
Using NCDU to reduce the number of files
There's not only a quota on the size of files, but also on the number of files. This is because the duration of many operations (e.g. the backups that are performed on your homedir) doesn't scale with file size, but with the amount of files. To have NCDU display the number of files stored in a certain directory, you can press 'c'. Let's do this on my home directory:

As you can see, it still shows (and orders by) the directory size on the left. But, we now also see an new number: the number of files in each directory. We can also sort by the number of files by pressing 'C' (i.e. shift + 'c').
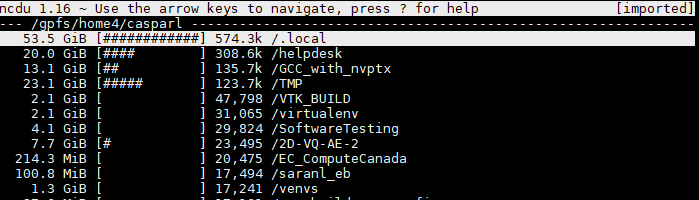
As you can see, it is again the '.local' folder that is the largest, with 574.3 thousand files in there. That's a lot! Going deeper into the directory tree, I find the largest software packages that I have installed in .local:

Anaconda3 is the largest by far: this single installation comes with 235.7k files. Since there is also a Miniconda3 installation available from the module environment, I don't really need this local Anaconda3 installation (their functionality is largely the same, but Miniconda3 is a lot more lightweight in terms of installation). Thus, I can easily remove it, and save myself 235.7k files.
Again, the situation might be very different for everyone. You might have a dataset where each sample is stored in a separate file. Or a simulation that creates a large amount of output files. In these cases, an easy solution might be to pack files together into a single aggregate file, such as a tarball or zip file. It does mean you'll have to do an extra step before/after your simulations (e.g. unpack the dataset on a scratch directory, or pack your simulation output before moving it to your homedir), but that's relatively easy to do.